英特尔针对阿里云通义千问2模型进行优化
为了最大限度地提升诸如阿里云通义千问2的大模型效率,全面的软件优化非常重要,其中包括从高性能融合算子到平衡精度和速度的先进量化技术。此外,英特尔还采用KV Caching、PagedAttention机制和张量并行来提高推理效率。英特尔的硬件可利用软件框架和工具包进行加速,并获得出色的大模型推理性能,其中包括PyTorch和英特尔® PyTorch扩展包、OpenVINO™工具包、DeepSpeed、Hugging Face库和vLLM。
英特尔与阿里云在数据中心、客户端以及边缘平台上的AI软件优化,有助于构建一个创新的生态环境,且截至目前,已取得了包括ModelScope、阿里云PAI、OpenVINO等在内的诸多创新成果。得益于此,阿里云AI模型可在多样化的计算环境中进行优化。
测试结果:英特尔® Gaudi AI加速器
英特尔Gaudi AI加速器专为生成式AI以及大模型的高性能加速而设计。使用最 新版本的英特尔Gaudi Optimum,可以轻松部署新型号的大模型。在英特尔Gaudi 2上对70亿参数和720亿参数的通义千问2模型的推理和微调吞吐量进行了基准测试,以下为详细性能指标和测试结果。
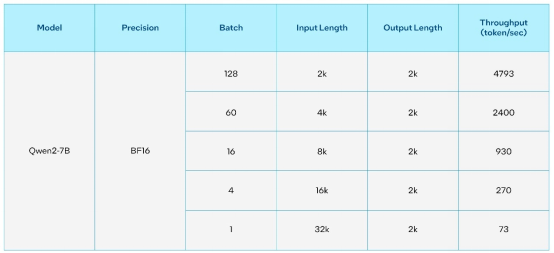
表1. 70亿参数的通义千问2在单颗英特尔Gaudi 2加速器上的推理
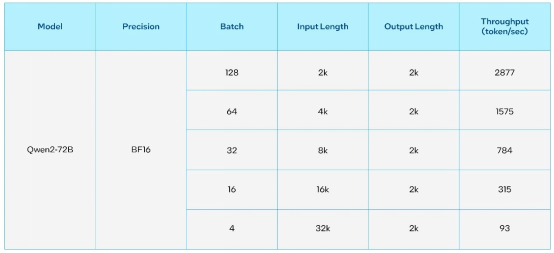
表2. 720亿参数的通义千问2在8颗英特尔Gaudi 2加速器上的推理
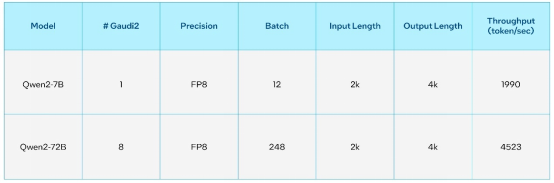
表3. 通义千问2 FP8在英特尔Gaudi 2加速器上的推理
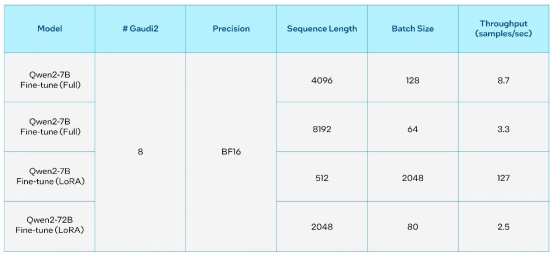
表4. 通义千问2在英特尔Gaudi 2加速器上的微调
测试结果:英特尔®至强®处理器
英特尔®至强®处理器作为通用计算的基石,为全球范围内的用户提供强大的算力。英特尔至强处理器具有广泛可用性,适用于各个规模的数据中心,这使其成为那些希望能够快速部署AI解决方案,又无需配备专项基础设施企业的理想选择。英特尔至强处理器的每个核心均内置了英特尔®高级矩阵扩展(英特尔AMX),可处理多样化的AI工作负载并加速AI推理。下图展现了英特尔至强处理器所提供的延迟性能可满足多种用例。
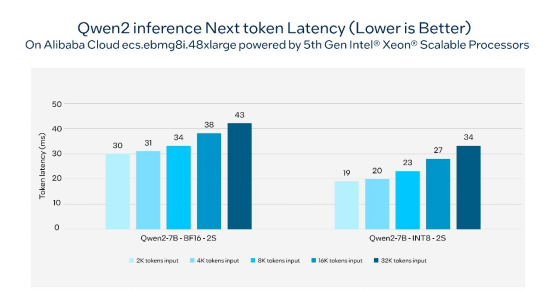
图1. 在基于第五代英特尔®至强®可扩展处理器的阿里云ecs.ebmg8i.48xlarge实例上,通义千问2的下一个推理token延迟
AI PC
由最 新英特尔®酷睿™ Ultra处理器和英特尔锐炫™显卡驱动的AI PC让AI的力量触及客户端和边缘,使开发者在本地也能部署大模型。AI PC配备了专门的AI硬件,如神经处理单元和内置的英特尔锐炫™显卡,或配备了英特尔® Xe Matrix Extensions加速的英特尔锐炫™ A系列显卡,以处理高需求的边缘AI任务。这种本地处理能力可实现个性化的AI体验,增强隐私性,并提供快速响应时间,这对于交互式应用程序至关重要。
以下展示了15亿参数的通义千问2,在基于英特尔®酷睿™ Ultra的AI PC上运行时所展现的强大性能。
Demo 1. 在内置英特尔锐炫™显卡的英特尔®酷睿™ Ultra 7 165H上,通义千问2的推理
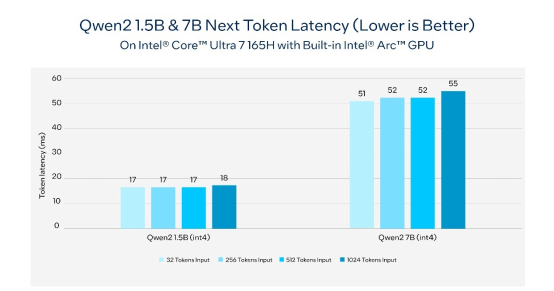
表2. 在内置英特尔锐炫™显卡的英特尔®酷睿™ Ultra 7 165H AI PC上,通义千问2的下一个token延迟
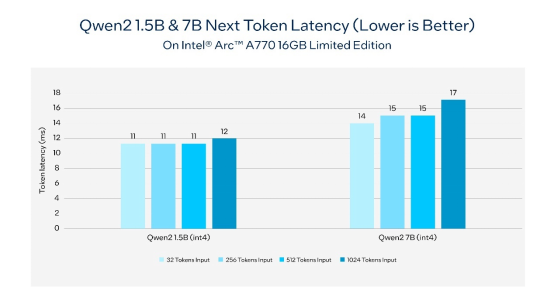
表3. 在由英特尔锐炫™ A770 16GB限量版驱动的AI PC上,通义千问2的下一个token延迟

